

TinyML, or tiny machine learning, focuses on deploying machine learning models on edge devices, unlocking benefits like enhanced privacy, independence from cloud connectivity, cost, and power efficiency. However, transitioning these models to production poses unique challenges. Renesas bridges this divide with the e-AI translator tool, transforming ML models from renowned frameworks like PyTorch, TensorFlow Lite, and Keras directly into C source code. This facilitates smoother collaboration between ML and embedded engineers. In this blog, we'll spotlight an application note detailing an end-to-end use case using the e-AI translator on our cloud kit, the CK-RA6M5, built around the RA6M5 device.
CK-RA6M5
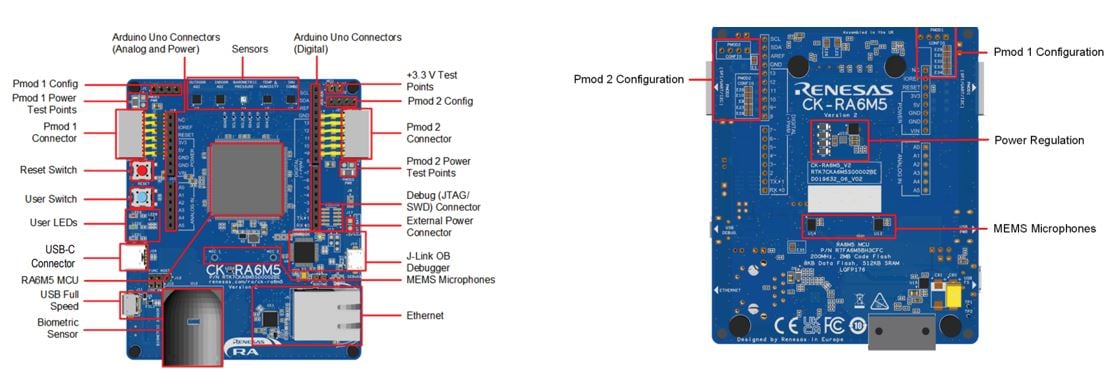
The CK-RA6M5 Cloud Kit [Figure 1] by Renesas stands at the forefront of cutting-edge solutions for developers keen on tapping into cloud capabilities, integrating seamlessly with the rich features of the Arm® Cortex®-M33 based RA6M5 group of MCUs.
Cloud Connectivity
- LTE Cellular CAT-M1 module RYZ014A ensures a robust global connection
- Ethernet options cater to a range of networking requirements
Sensors
- Humidity and temperature
- Indoor and outdoor air quality indexes
- Health-related: Heart rate, SpO2 (blood oxygen saturation), and respiration rate
- Barometric pressure and 9-axis motion tracking
- Two MEMS microphones for varied audio applications
Onboard MCU
- RF7A6M5BH3CFC microcontroller
- Operates at a brisk 200MHz on an Arm Cortex-M33 core
- 2MB Code Flash complemented by 512KB SRAM
- Comes in a compact 176-pin LQFP package
Additional Features
- USB Full Speed, adaptable for both Host and Device
- Arduino™ (Uno R3) connector ensuring compatibility with a range of modules
- Endorsed by Renesas Flexible Software Package (FSP) that integrates FreeRTOS, Azure RTOS, and other vital middleware stacks
The CK-RA6M5 kit is a clear reflection of Renesas' dedication to streamlining cloud integrations and offering developers a swift passage from conception to market.

e-AI Translator
As mentioned earlier, the e-AI translator is Renesas' developed tool to translate AI models from popular frameworks into C-source code. The frameworks are PyTorch, TensorFlow Lite, and Keras. Figure 3 shows the GUI of the e-AI translator.
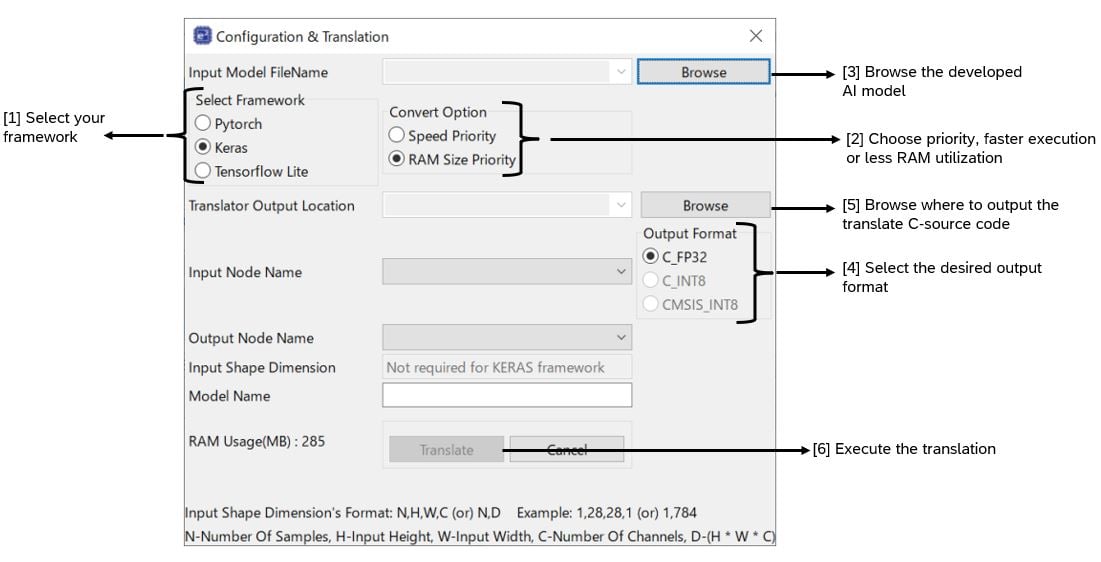
Figure 3 numbering showcases the order necessary to execute the translation as follows:
- Select the framework utilized to develop the ML model.
- Select whether the translation should prioritize inference speed or prioritize RAM consumption, this affects the end output C-code.
- Select your AI model file.
- Choose the desired output format, either FP32, INT8 executed via reference kernels or CMSIS NN kernels that have been developed by Arm and provided a significant uplift in execution speed.
- Browse where to place the translated C-source code, i.e., in the embedded project directory.
- Execute the translation and you should see a new folder with various files including the source files and a checker_log_output.txt file to confirm the model translated along with RAM/ROM usage.
For further information and details on the e-AI translator tool, please visit our e-AI Development Environment for Microcontrollers page and access the e-AI translator user manual.
End-to-End Workflow to Realize Endpoint Voice Recognition
The following section will gently introduce the developed application note that provides a detailed step-by-step explanation of the entire Keyword spotting TinyML development pipeline from data cleaning to the embedded application code to realize the use case, the workflow can be seen in Figure 4. This example leverages the open-source keyword spotting dataset published by Google [4].
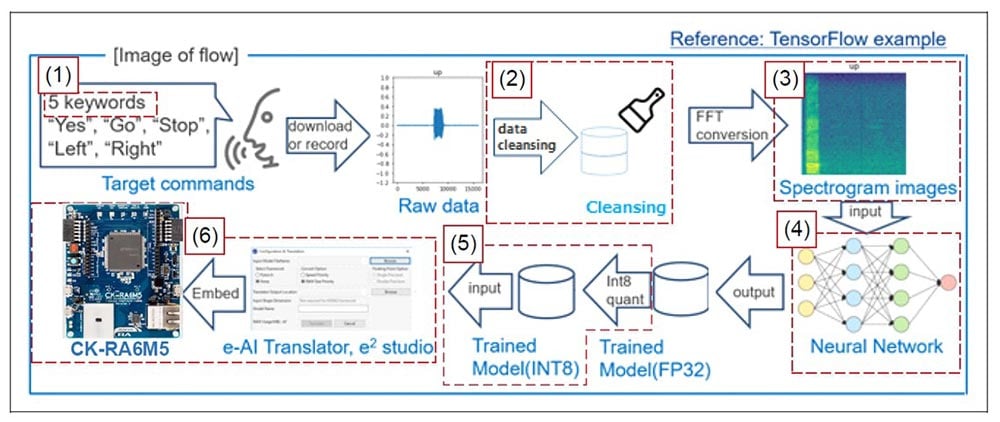
- Target Keywords: For ease of demonstration, the voice keyword system has been limited to recognizing five specific keywords: go, left, right, stop, and yes.
- Preprocessing: In deep learning, noisy or incomplete data can reduce model accuracy. Considering the limited model capacity available due to the severe constraints of MCUs, more efficient preprocessing techniques have been employed.
- Data Cleansing: The data cleansing involved in this example is amplifying or attenuating the recording levels to maintain consistency, followed by removing nearly silent and anomalous data, ensuring that only ideal speech data is retained. Cropping out the silent sections results in the data being left-aligned, aligning the start positions of the speech data.
- Conversion to Spectrograms: As a convolution neural network is employed, which excels at images, the audio data are converted into spectrograms which are a visual representation of the spectrum of frequencies of a signal as they vary with time. To accommodate a microcontroller's small memory, the spectrogram data size is capped at 64 by 62 points, aligning with a one-second audio clip at a 16,000 Hz sampling rate from the Google mini–Speech Commands dataset. The program averages adjacent points to reduce the data volume, ensuring keyword recognition within these memory constraints.
- Neural Network: The optimized neural network has been designed using TensorFlow Keras API which consists of 2 convolution layers, 2 maxpooling layers, and a flattened dense layer which yielded an accuracy of over 90%.
- Trained Model Configuration: The trained model has then been quantized to INT8 format to reduce memory utilization without an effect on accuracy, this was done by calibrating the model using representative training data during the conversion to ensure optimal quantization boundaries, preserving the model's accuracy.
- Integration with e-AI Translator and CK-RA6M5: As mentioned in the previous section, the e-AI Translator would then translate the .H5 file into a C-source code to be utilized in the embedded project. The application code is then developed as shown in Figure 5 utilizing the CK-RA6M5 board.
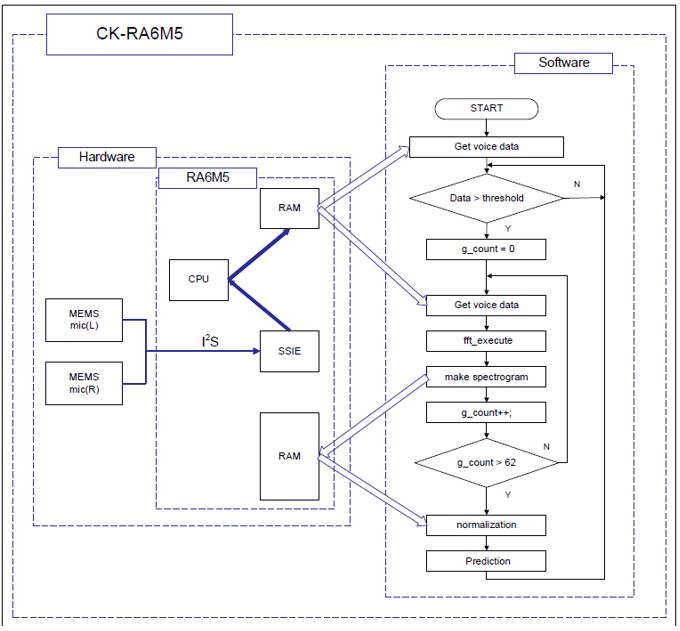
Upon running the application code on the device, the following behaviors can be observed:
- Initially, the LED lights up, indicating the system is not ready for audio input.
- When the LED turns off, the device awaits speech input.
- After detecting speech, the LED lights up for 1 second, during which speech recognition takes place.
- The CK-RA6M5 processes the 1-second speech input with amplification, left alignment, FFT, and normalization, followed by inference.
- The result of the inference is shown through the LED blinks on the CK-RA6M5:
- 1 blink for "Go"
- 2 blinks for "Left"
- 3 blinks for "Right"
- 4 blinks for "Stop"
- 5 blinks for "Yes"
We hope this guide was helpful to get you started and teach you how to utilize our e-AI translator tool effectively.
For more details and the scripts for preprocessing, model development, and the embedded application project, please visit the e-AI Development Environment for Microcontrollers webpage and access the application note under “Tutorial Guide”.
Reference
[1] e-AI Development Environment for Microcontrollers
[2] CK-RA6M5
[3] RA6M5 Microcontroller
[4] Pete Warden, "Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition", Apr. 2018