NEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)が進める「高効率・高速処理を可能とするAIチップ・次世代コンピューティングの技術開発」でルネサス エレクトロニクス(株)は、複雑なタスクを処理する動的再構成プロセッサー(DRP)を用いた人工知能(AI)チップを開発しました。電力効率は1W(ワット)当たり10TOPS(10兆回/秒)で、従来技術に比べて最大で10倍の電力効率を実現しました。
このAIチップは、ルネサス独自のAIアクセラレーター「DRP-AI」と電力効率をさらに高めるAI軽量化技術を組み合わせて開発しました。これにより低消費電力かつリアルタイムで応答するAI機器として、セキュリティカメラや自動搬送車、サービスロボットなどのさまざまな装置内に組み込む設置が可能になります。さらに、現場の環境やタスクの変化にも自律対応するエンドポイント学習システムも開発し、基本動作を実証しました。

図1 動的再構成プロセッサー(DRP)を用いた人工知能(AI)チップと多様な産業機器への搭載
1.概要
少子高齢化に伴い労働人口が減少する中、工場、物流、医療など社会のさまざまな場面で稼働するサービスロボットやセキュリティカメラに組み込め、高度な人工知能(AI)処理を行い、リアルタイムで応答するAI機器が求められています。さらに、AIの活用を促進するためには、機器が置かれる環境に柔軟に適合するAI技術の開発なども併せて求められます。
一方、AI処理には大量の演算が必要となるため、既存のAIチップでは消費電力の増大による発熱が実用化の障害となっています。例えばこれまで、カメラやロボットなどの装置内にAIチップを搭載するためには、発熱抑制のためのファンを設置する必要があり、実装コストの増大やスペースの確保、ファンの騒音や故障などが課題でした。これらの課題を解消するためには、100W(ワット)クラスのPCで行うような高度なAI処理を数W以内で行う性能が必要です。
このような背景のもと、NEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)が進める「高効率・高速処理を可能とするAIチップ・次世代コンピューティングの技術開発※1」で、ルネサス エレクトロニクス株式会社(ルネサス)は、国立大学法人東京工業大学、SOINN株式会社、三菱電機株式会社と連携し、複雑なタスクを処理する動的再構成プロセッサー(DRP:Dynamically Reconfigurable Processor)※2をベースに、高度なAI処理を低消費電力で動作させる組み込みAIチップの実用化を目指し、アーキテクチャーと設計支援ツールの開発を進めています。
このたび、ルネサスはDRPを用いて高いAI処理性能と低消費電力を兼ね備えた独自のAIアクセラレーター※3「DRP-AI」と、電力効率をさらに高めるAI軽量化技術を組み合わせたAIチップを開発し、従来技術比で最大10倍となる1W当たり10TOPS(兆回/秒)※4の電力効率を実現しました。さらに、DRPを活用し、現場の環境やタスクの変化にも自律的に対応できるエンドポイント※5学習システムも開発し、その基本動作を実証しました。
2.今回の成果
ルネサス独自のAIアクセラレーター「DRP-AI」をベースとした次世代AIアクセラレーターの開発
今回開発したAIチップは、ルネサス独自のDRPをベースとしています。チップ内の演算器の回路接続構成を処理内容に応じて動作クロック※6ごとにダイナミックに切り替えながらアプリケーションを実行可能で、必要な演算回路だけが動作するため、消費電力が小さく、高速化も可能になります。このDRPと積和演算ユニット(AI-MAC)※7を一体化したものが、AIアクセラレーターとなる「DRP-AI」です。今回、この「DRP-AI」をベースに、軽量化したAIモデルを効率的に処理できる次世代AIアクセラレーターを開発しました。
演算量を最大90%削減するAI軽量化技術の開発
代表的なAIモデル軽量化手法のうち、認識精度に影響の少ない演算を省略する「枝刈り※8」によってAI処理を高速化しました。
AIモデル内で認識精度に影響のない演算は不規則に存在することが一般的です。そのため、ハードウエア処理の並列性と枝刈りの不規則性とに差があり、効率よく処理できないことが大きな課題となっていました(図2)。
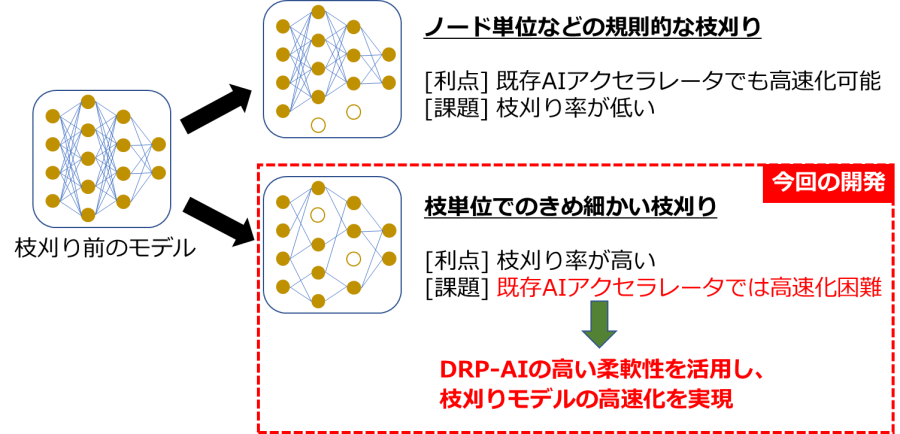
図2 「DRP-AI」による枝刈りAIモデルの高速化
今回開発したAIアクセラレーターは、「DRP-AI」が持つ動的な回路切り替え技術などの高い柔軟性を活用することで、枝単位できめ細かく枝刈りした場合でも効率よく演算をスキップすることができます。これにより、認識精度に必要な演算のみに絞りつつ、高いハードウエア並列性を維持して処理できるようになります。演算量を最大90%削減する枝刈り率※9のAIモデルにおいて、従来技術に比べ最大で10倍の高速化を実現し、1W当たり最大で10TOPSの電力効率を達成しました。また、モデルにもよりますが、枝刈りにより演算量を90%削減した場合でも、認識精度はわずか3%程度の低下にとどまり、ほぼ同等の精度が得られることを確認しました(図3)。

図3 電力効率の比較(左)、枝刈りによる演算量削減率と認識精度との関係(右)
さらに、ユーザーが多様なAIモデルを容易に実装できるように、枝刈りモデルの最適化からハードウエア実装までエンドツーエンドで自動化するAI実装ツールを開発しました。
これにより、「高い性能と低消費電力」と「AIの進化に対応できる柔軟性」を両立し、高精度なAIの実行が可能なAIアクセラレーターの開発に成功しました。
環境に自律的な対応ができるエンドポイント学習システムの構築
AIを搭載したシステムを実環境で使用する際の課題の一つとして、機器の設置場所やセンサーのばらつきに応じて認識精度が変わってしまうという問題がありました。その解決には、装置が設置される環境で、ニューラルネットワークの一部を再度学習させる追加学習が有効となります。これまで、クラウド上で追加学習するシステムはありましたが、クラウドとの通信環境の確保やプライバシーの問題、学習サーバーのコスト増などが問題となっていました。今回、DRPが学習アルゴリズムの実装まで可能な高い柔軟性を有することを利用し、「DRP-AI」内でAIの実行と追加学習を同時並行して実行するエンドポイント学習技術を開発しました(図4)。

図4 環境に自律的に対応し、リアルタイムで応答するエンドポイント学習システムの概要
これにより、現場の動作環境やタスクの変化に自律的に適応していくエッジでの学習システムを構築することが可能となりました。また、AIの実行を止めずにバックグラウンドで学習することが可能となるため、追加学習のための時間の確保やデータ収集の手間が不要となり、運用が容易になりました。これにより、機器の設置場所やセンサーのばらつきによらず、リアルタイムで応答する高精度な組み込みAIの実行が可能になりました。
実証
本技術を搭載したAIチップを試作し、10分の1に軽量化された畳み込み層※10の性能評価を実施した結果、製品化されているエンドポイント機器向けAIプロセッサーとしては世界トップレベルの実効効率(1W当たり10TOPS)を実証しました。ルネサスの現行製品と比べても10倍以上の電力効率となります(図3)。
3.今後の予定
NEDOと各機関が連携し、本技術に関する詳細評価および実証実験を進めます。また、ルネサスは本研究成果のAI技術をいち早く実用化につなげるため、IoTインフラ事業向け製品への適用を計画しています。本技術の確立により、スマート市場やロボティクスなどさまざまな産業での自動化を拡大し、デジタルトランスフォーメーション(DX)の加速による新サービスの創造にも貢献します。
注釈
※1 高効率・高速処理を可能とするAIチップ・次世代コンピューティングの技術開発
研究開発項目:革新的AIエッジコンピューティング技術の開発/動的再構成技術を活用した組み込みAIシステムの研究開発
事業期間:2018年度~2022年度
※2 動的再構成プロセッサー(DRP:Dynamically Reconfigurable Processor)
DRPは演算器間の接続を動的に切り替えながらアプリケーションを実行するルネサス独自のハードウエアであり、画像処理など並列性の高いアルゴリズムを従来の組み込みプロセッサーに比べ10倍以上高速に処理できます。DRPはハードウエアロジックの高い処理能力と、CPUのような高い柔軟性・機能拡張性を併せ持ったIPコアです。
※3 AIアクセラレーター
AIアプリケーション、特にニューラルネットワークなどの、機械学習を行うために開発されたアルゴリズムを実行するエンジン(機能単位)です。DRPと積和演算に特化した演算ユニットを一体化したものがDRP-AIです。詳細は下記のルネサスのDRP-AIホワイトペーパーをご参照ください。
ホワイトペーパー 組み込みAIアクセレーター(DRP-AI)
https://www.renesas.com/jp/ja/document/whp/embedded-ai-accelerator-drp-ai
※4 TOPS(兆回/秒)
TOPS(tera operations per second)として1秒当たりの電力効率を表す単位です。この数値が大きいほど、ある問題をある速度で処理する際の消費電力が小さいため、高効率であるといえます。
※5 エンドポイント
ネットワークに接続された端末の装置のことで、モバイル端末やネットワークカメラ、家電、ロボットなど幅広い機器に用いられています。
※6 クロック
CPUなど、一定の波長を持って動作する回路が、処理の歩調をあわせるために用いる信号のことです。波長の山と谷とで1クロックをなし、CPUやメモリーの行う処理は1クロックを1周期とします。
※7 積和演算ユニット(AI-MAC)
ニューラルネットワークの演算で多用される積和演算(Multiply and Accumulation)に特化した演算ユニットのことです。大量の積和演算器による並列処理によって、ニューラルネットワークの高速処理が可能になります。
※8 枝刈り
ニューラルネットワークの認識精度を保ちつつ、必要計算量・メモリー容量を削減するために、ニューロン(特徴マップのベクトル次元)やシナプス結合(重み係数の要素)の一部を省略するアルゴリズムです。係数の要素のうち、絶対値の小さいものから一定の割合で0に置き換えて再学習するなどの手法が用いられます。
※9 枝刈り率
AIモデルのうち、何%の演算を省略できるかを示した値です。この値が大きいほど、ニューラルネットワークの計算量・メモリーを削減できます。
※10 畳み込み層
画像の中から特徴点を抽出する演算です。画像認識AIで処理の大半を占めるため、畳み込み層の処理能力の高さが、AI全体の性能に大きく影響します。
以 上
*本リリース中の製品名やサービス名は全てそれぞれの所有者に属する商標または登録商標です。
ニュースリリースに掲載されている情報(製品価格、仕様等を含む)は、発表日現在の情報です。 その後予告なしに変更されることがございますので、あらかじめご承知ください。