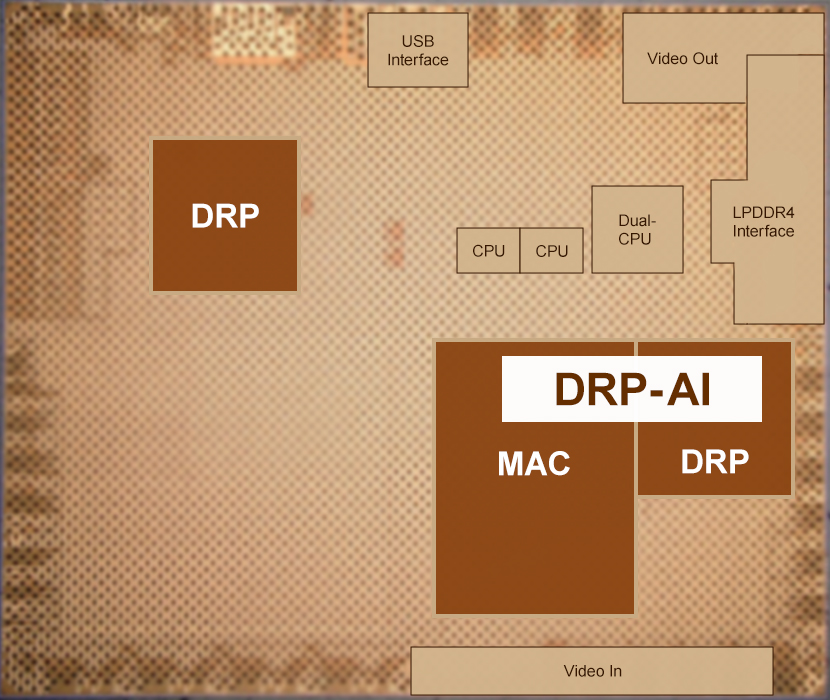
ルネサス エレクトロニクス株式会社(代表取締役社長兼CEO:柴田 英利、以下ルネサス)は、このたび、高度なビジョンAIを実現するMPU(Micro Processor Unit)を、高速化、低消費電力化する組み込みプロセッサ技術を開発しました。今回新たに開発した技術は、(1)軽量化したAIモデルを効率よく処理できる動的再構成プロセッサ(Dynamically Reconfigurable Processor: DRP)ベースのAIアクセラレータ、(2)CPUなど各種IPを協調動作させることによりリアルタイム処理を実現するヘテロジニアスアーキテクチャ技術です。これらの技術を搭載した組み込みAI-MPUを試作し、高速かつ低消費電力動作を実証しました。その結果、新技術の導入前に比べて最大16倍の処理性能(130TOPS)を実現し、さらに世界トップレベルの電力効率(最大23.9 TOPS/W(0.8V動作時))を達成しました。
昨今、工場、物流、医療、店舗等でロボットが普及する中、高度なビジョンAIにより周囲を認識し、リアルタイムに自律して動作するシステムが求められています。高性能化はもちろん、特に組み込み機器では発熱に対する制約が厳しいため、AIチップの低消費電力化がより一層求められています。ルネサスは、これらの要求に応えるために新技術を開発し、その成果を2024年2月18日から22日までサンフランシスコで開催されている「国際固体素子回路会議 ISSCC 2024 (International Solid-State Circuits Conference 2024)」で、2月21日に発表しました。
ルネサスが新たに開発した技術は以下の通りです。
(1)軽量化したAIモデルを効率よく処理するAIアクセラレータ
AIの処理効率を高める代表的な技術として、認識精度に影響の少ない演算を省略する「枝刈り」手法があります。しかしながら、AIモデル内で認識精度に影響が無い演算は不規則に存在することが一般的です。そのため、ハードウェア処理の並列性と枝刈りの不規則性とに差があり、効率よく処理できないことが課題となっていました。
ルネサスは、この課題を解決するために、独自のDRPベースのAIアクセラレータ(DRP-AI)を枝刈り処理に最適化しました。代表的な画像認識向けAIモデル(CNNモデル)における枝刈りパターンの特徴や枝刈り方式と認識精度との関係を分析し、高い認識精度と枝刈り率を両立可能なAIアクセラレータのハードウェア構造を特定し、DRP-AIの設計に反映しました。さらに、このDRP-AI向けに最適化したAIモデルを軽量化するソフトウェアを開発しました。本ソフトウェアで不規則な枝刈りモデルの構成を高効率な並列演算処理に変換することにより、AI処理の高速化が可能になりました。特に、AIモデル内の局所的な枝刈り率の変化に応じてサイクル数を動的に切り替えることが可能な柔軟性の高い枝刈り対応技術(フレキシブルN:M枝刈り技術)により、ユーザが必要とする消費電力や動作速度、認識精度に応じて枝刈り率を細かく調整することが可能となりました。
本技術により、AIモデルの処理サイクル数を枝刈りモデル対応前と比較して最小で1/16まで削減するとともに、消費電力も最小で約1/8以下にすることが可能になります。
(2)ロボット制御に向けてリアルタイム処理を可能にするヘテロジニアスアーキテクチャ技術
ロボットアプリケーションでは、周辺環境の認識などに高度なビジョンAI処理が求められます。一方、ロボットの行動判断や制御では、周辺環境の変化に応じて条件を細かくプログラムする必要があるため、AIではなく、CPUによるソフトウェア処理が適しています。この時、現在の組み込みプロセッサのCPUでは、リアルタイムに動作制御するための性能が足りないことが課題になっています。そこでルネサスは、CPUとAIアクセラレータ(DRP-AI)に加え、複雑な処理を担う動的再構成プロセッサ(DRP)を搭載しました。適材適所に処理を分配し、並列動作させることで、AI-MPUの高速化と低消費電力化を実現するヘテロジニアスアーキテクチャ技術を開発しました。
DRPは、チップ内の演算器の回路接続構成を処理内容に応じて動作クロックごとに動的に切り替えながらアプリケーションを実行できます。複雑な処理でも、必要な演算回路だけが動作するため、消費電力が小さく、高速化も可能です。たとえばロボットアプリケーションの代表例の一つであるSLAM(Simultaneously Localization And Mapping)は、ビジョンAI処理による環境認識と並行して、ロボット位置認識のための複数のプログラム処理が必要になる複雑な構成です。これをDRPにより瞬時にプログラムを切り替えながら実行し、さらにAIアクセラレータやCPUとの並列動作により、組み込みCPU単独動作に比べて約17倍の高速動作や、消費電力を1/12程度に削減できることを実証しました。
動作実証
ルネサスは、本技術を搭載したテストチップを試作し、通常の電源電圧(0.8V)におけるAIアクセラレータの最大電力効率は、世界トップレベルとなる1ワットあたり23.9TOPSを達成し、主要なAIモデル動作時の電力効率は1ワット当たり10TOPSを実証しました。また、ファンやヒートシンクなしでAI処理を行うことが可能であることを示しました。
これらの成果を活用することにより、これまでサービスロボットや自動搬送車など多様な組み込み機器へのAI実装課題であった消費電力の増大による発熱の解決が可能となり、ロボティクスやスマート市場などさまざまな産業での自動化の拡大に貢献できます。なお、これらの技術はビジョンAIアプリケーション用MPU 「RZ/Vシリーズ」に適用する予定です。
以 上
(注) なお、本技術は、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の委託業務の成果を一部活用しています。
*本リリース中の製品名やサービス名は全てそれぞれの所有者に属する商標または登録商標です。
ニュースリリースに掲載されている情報(製品価格、仕様等を含む)は、発表日現在の情報です。 その後予告なしに変更されることがございますので、あらかじめご承知ください。