
なりすまし防止とは何でしょうか?何故重要だと思いますか?
なりすまし対策は、模倣された音声を伴う詐欺行為や、偶発的に音声認識のトリガーが実行される事を防ぎ、VUIシステム全体のUI/UXを向上させるために開発された技術です。 この手法は、以下のような問題を防ぐために特に重要です。
- 音声合成(Speech Synthesis): この手の攻撃は、コンピュータでシミュレートされた音声が使用されます。
- 音声変換(Voice Conversion): この攻撃では、フィルタやその他のツールを使用して、標的となった人の声にできるだけ近づけます。
- リプレイ攻撃 (Replay Attack): 標的となった個人の音声を事前に録音し、それを使用します。
- なりすまし: このタイプの攻撃では、攻撃者がターゲットの人の声の調子、韻律の特徴、語彙などの特徴を模倣します。
- 想定しないトリガー: これは、人工的な音声が誤ってシステムを動作させ、ユーザーに不便をもたらす場合。

これらの攻撃や意図しない動作は、音声システムを使用する上での顧客エクスペリエンスに重大な混乱を引き起こす可能性があるため、堅牢なソリューションが必要です。
なりすまし防止はどのように機能するか?
対策としては、録音された音声、コンピュータで生成された音声、またはコンピュータ上で模倣された音声が関与したなりすまし攻撃を検出して防止することによって機能します。 ここでは、その仕組みの主な構成要素をいくつか紹介します。

- キーワードの検出(Detecting keyword): システムは、誰が話しているかや、コマンドをトリガーすべきかを識別する必要があります。 例: 「Hi Renesas」でシステムがトリガーされる。
- 特徴の抽出(Feature Extraction): 音色、アーティキュレーション、イントネーション、語彙動作などの特徴を入力音声信号から抽出します。
- なりすまし音声の検出 (Spoof Speech Detection/SSD): この一連の対策は、なりすまし音声による攻撃を識別して防止するために使用されます。 たとえば、リプレイ攻撃により、人の耳では区別できない特定の信号アーティファクトが生成されます。 高度なアルゴリズムがそのようなアーティファクトを見つけて識別し、活性度を正確に判断します。
- 分類(classification): 特徴を抽出した後、分類器を使用して音声を本物か録音されたものかに分類します。
これらの技術を使用することで、なりすまし音声防止システムは、さまざまな種類のなりすまし音声による攻撃に効果的に対抗し、ユーザーエクスペリエンスを向上させることができます。例えば、あなだがどこにいても、自宅のスマートドアロックの前にいるのが本当に顔見知りのご近所さんかどうかを見極める事ができます。
ルネサスのアプリケーション例:
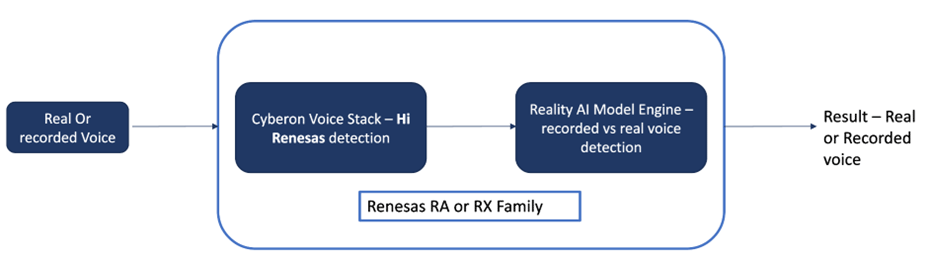
ルネサスの音声なりすまし防止は、高い精度を維持しながら速度と応答性を実現するように設計されており、完全にエッジで行われます。RA ファミリ (RA6、RA4、RA2シリーズ) および RX ファミリのハードウェアに、 Cyberon DSpotter の音声スタックと組み合わせてトリガー/ウェイクワードを識別し、Reality AIによる 生成モデルを使用して、実際の音声と録音された音声を信号内でチェックします。
ルネサスの Reality AI モデルは、ウェイクワードとして Hi Renesas を使用しています。 ユーザーは一般的な英語のアクセントと自然な声の音質 (男性または女性) で話して使う事ができます。 私たちのテストでは、電話のスピーカー (iPhone または Android) から再生される録音音声に対し96% の制度と、K-分割検証を使ったトレーニングでは ~99% の精度であることがベンチマークされました。
このアプリケーション例はどのようにして作成するのか?
ルネサスの 統合開発環境/IDEのe² studio を利用し、ユーザーはデータの収集と、ウェイクワード検出用に Cyberon の Voice Stack (Hi Renesas)を組み合わせ、最後に Reality AI Tools モジュールを使用して生成された AI モデルを統合しています。
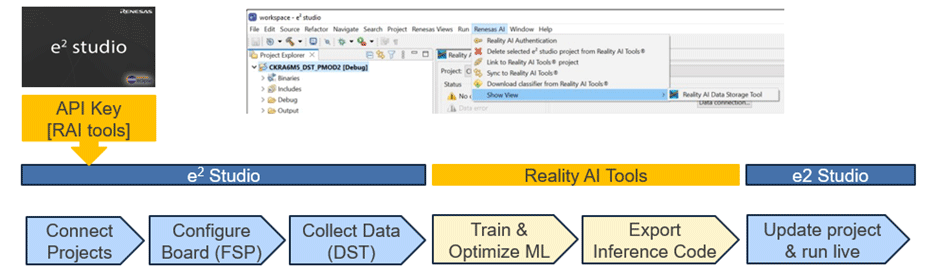
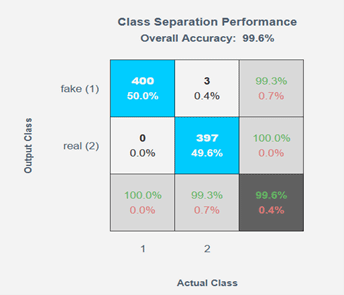
私たちは、少人数の人々から実際のデータ (ルネサスのハードウェアマイクを介して録音) と記録データを収集しました。 このデータは、Reality AI の特徴抽出およびトレーニング エンジンに供給されて、モデル開発および出力しました。私たちは、K分割精度 ~99% を達成したため、ライブ テストとベンチマーク用のモデルを選択することになりました。
その後、モデルをe² studioに再度統合します。 更に、このモデルを使ってベンチマークも実施しています。トレーニング セットに含まれていない人々の音声を実際のオフィス環境下でテストした所、96% の精度を達成しました。
このアプリケーション例を皆さんのVUIシステムに組み込み、参考として使用する事で、開発を簡素化する事が可能になります。詳細については、Reality AI Toolsのページをご覧いただくか、最寄りの営業担当者にお問い合わせください。
最後に
ルネサスの音声なりすまし防止のアプリケーション例は、UX を改善し、VUI システムを強固にするReality AI Toolsの可能性を示しています。 当社の AI モデルはコード面積が小さく、広範なデータ収集を利用して拡張できる柔軟性を備えています。
ダウンロード
| 分類 | タイトル | 日時 |
|---|---|---|
| サンプルコード | [Software=RA Flexible Software Package|v] ZIP 13.75 MB アプリケーション: ヒューマン・マシン・インタフェース (HMI), 人工知能, 民生機器全般, 産業用機器, 自動車, 通信インフラストラクチャ Compiler: ARMCC Function: Application Example IDE: e2 studio | |
1件 | ||


