
The Internet of Things is exploding. Devices are connected and communicating with one another, enabled by ubiquitous wired and wireless connectivity. This hyper-connectivity allows collection of massive amounts of data that can be harvested, analyzed and used to make intelligent decisions. The ability to draw insights from data and make autonomous decisions based on these insights is the essence of Artificial Intelligence (AI). The combination of AI and IoT or Artificial Intelligence of Things (AIoT), enables the creation of “intelligent” devices that learn from data and make decisions without human intervention.
There are several drivers of this trend to build intelligence on edge devices:
- Decision-making on the edge reduces latency and cost associated with cloud connectivity and makes real-time operation possible
- Lack of bandwidth to the cloud drives compute and decision making onto edge devices
- Security is a key consideration – requirements for data privacy and confidentiality drive the need to process and store data on the device itself
AI at the edge, therefore, provides advantages of autonomy, lower latency, lower power, lower bandwidth requirements, lower costs and higher security, all of which make it more attractive for new emerging applications and use cases.
The AIoT has opened up new markets for MCUs, enabling an increasing number of new applications and use cases that can use MCUs paired with some form of AI acceleration to facilitate intelligent control on edge and end point devices. These AI-enabled MCUs provide a unique blend of DSP capability for compute and machine learning (ML) for inference and are being used in applications as diverse as keyword spotting, sensor fusion and vibration analysis. Higher performance MCUs enable more complex applications in vision and imaging such as face recognition, fingerprint analysis and object detection.
Neural networks are used in AI / ML applications such as image classification, person detection and speech recognition. These are basic building blocks used in implementing machine learning algorithms and make extensive use of linear algebra operations such as dot products and matrix multiplications for inference processing, network training and weight updates. As you might imagine, building AI into edge products requires significant compute capability on the processors. Designers of these new, emerging AI applications need to address demands for higher performance, larger memory and lower power, all while keeping costs low. In days past, this was the purview of GPUs and MPUs with powerful CPU cores, large memory resources and cloud connectivity for analytics. More recently, AI accelerators are available that can offload this task from the main CPU. Other edge compute applications such as audio or image processing require support for fast multiply-accumulate operations. Often, designers opted to add a DSP into the system to handle the signal processing and computational tasks. All these options provide the high performance required but add significant cost to the system and tend to be more power hungry and thus not suitable for low-power and low-cost end point devices.
How can MCUs fill the gap?
The availability of higher performance MCUs allows low cost, low power edge AIoT to become a reality. AIoT is enabled by higher compute capability of recent MCUs, as well as thin neural network models that are more suited for resource-constrained MCUs used in these end point devices. AI on MCU-based IoT devices allows real-time decision making and faster response to events, and also brings the advantages of lower bandwidth requirements, lower power, lower latency, lower costs and higher security than MPUs or DSPs. MCUs also offer faster wake times which enable faster time to inference and lower power consumption, as well as higher integration with memory and peripherals to help lower overall system costs for cost-sensitive applications.
The Cortex-M4 / M33 based MCUs can address the needs of simpler AI use cases such as keyword spotting and predictive maintenance tasks with lower performance needs. However, when it comes to more complex use cases such as vision AI (object detection, pose estimation, image classification) or voice AI (speech recognition, NLP), a more powerful processor is required. The older Cortex-M7 core can handle some of these tasks but the inference performance is low, typically only in the 2-4 fps range.
What is needed is a higher performance microcontroller with AI acceleration.
Introducing the RA8 Series high-performance AI MCUs
The new RA8 series MCUs featuring the Arm Cortex-M85 core based on the Arm v8.1M architecture and a 7-stage superscalar pipeline, provide the additional acceleration needed for the compute intensive neural network processing or signal processing tasks.
The Cortex-M85 is the highest performance Cortex-M core and comes equipped with Helium™, the Arm M-Profile Vector Extension (MVE) introduced with the Arm v8.1M architecture. Helium is a Single Instruction Multiple Data (SIMD) vector processing instruction set extension which can provide performance uplift by processing multiple data elements with a single instruction, such as repetitive multiply accumulates over multiple data. Helium significantly accelerates signal processing and machine learning capabilities in resource constrained MCU devices and enables an unprecedented 4x acceleration in ML tasks and 3x acceleration in DSP tasks compared to the older Cortex-M7 core. Combined with large memory, advanced security and a rich set of peripherals and external interfaces, the RA8 MCUs are ideally suited for voice and vision AI applications, as well as compute intensive applications requiring signal processing support such as audio processing, JPEG decoding and motor control.
What RA8 MCUs with Helium enable
The Helium performance boost is enabled by processing wide 128-bit vector registers that can hold multiple data elements (SIMD) with a single instruction. Multiple instructions may overlap in the pipeline execution stage. The Cortex-M85 is a dual-beat CPU core and can process two 32-bit data words in one clock cycle, as shown in Figure 1. A Multiply-Accumulate operation requires a load from memory to a vector register followed by a multiply accumulate, which can happen at the same time as the next data is being loaded from memory. The overlapping of the loads and multiplies enables the CPU to have double the performance of an equivalent scalar processor without the area and power penalties.
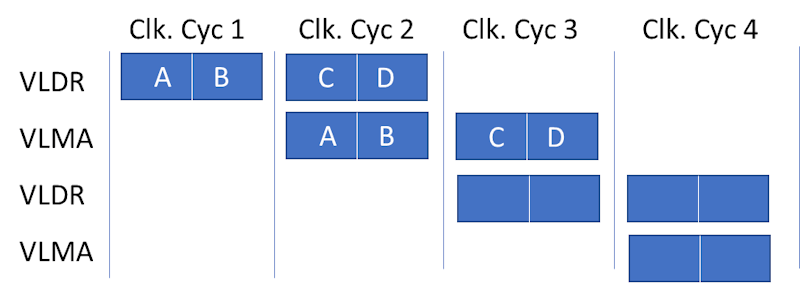
Helium introduces 150 new scalar and vector instructions for acceleration of signal processing and machine learning including:
- Low Overhead Branch Extension (LOBE) for optimized branch and loop operations
- Lane predication that allows conditional execution of each lane in a vector
- Vector gather-load and scatter-store instructions for reads and writes to non-contiguous memory locations useful in implementation of circular buffers
- Arithmetic operations on complex numbers such as add, multiply, rotate used in DSP algorithms
- DSP functions such as circular buffers for FIR filters, bit reversed addressing for FFT implementations format conversion in image and video processing
- Polynomial math that supports finite field arithmetic, cryptographic algorithms and error correction
- Support for 8, 16 and 32-bit fixed point integer data used in audio/image processing and ML and half, single and dual precision floating point data used in signal processing
These features make a Helium-enabled MCU particularly suited for AI / ML and DSP-style tasks without an additional DSP or hardware AI accelerator in the system and also lowering costs and power consumption.
Voice AI Application with RA8M1 MCUs
Renesas has successfully demonstrated this performance uplift with Helium, in a few AI / ML use cases, showing significant improvement over a Cortex-M7 MCU – more than 3.6x in some cases. One such application is a voice command recognition use case that runs on the RA8M1 and implements a deep neural network (DNN) that is trained with thousands of diverse voices and supports over 40 languages. This voice application presents an enhancement over simple keyword spotting and supports a modified form of Natural Language Understanding (NLU) that does not depend only on the command word or phrase, but instead looks for intent. This enables the use of more natural language without having to remember exact key words or phrases.
The voice implementation makes use of the SIMD instructions available on the Cortex-M85 core with Helium. RA8M1 is a natural fit for these kinds of voice AI solutions with its large memory, support for audio acquisition and above all, the high performance and ML acceleration enabled by the Cortex-M85 core and Helium. Even the preliminary implementation of this solution with and without Helium demonstrates more than 2x inference performance improvement over the Cortex-M7 based MCU, as shown in Figure 2.
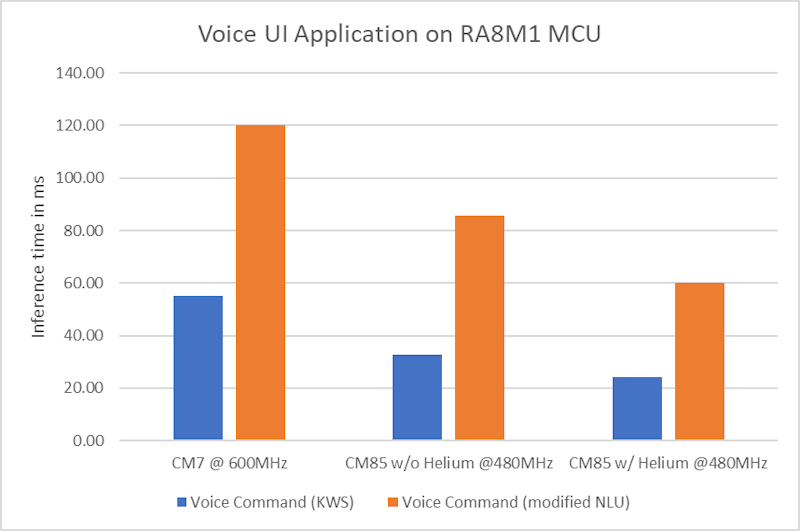
As is evident, RA8 MCUs with Helium can significantly improve neural network performance without the need for any additional hardware acceleration, thus providing a low-cost, low-power option for implementation of simpler AI and machine learning use cases.
References
The following documents are referenced in this article:
- “Arm® Helium™ Technology, M-Profile Vector Extension (MVE) for Arm® Cortex®-M Processors”, by Jon Marsh, Arm
- “Introduction to Armv8.1-M architecture” By Joseph Yiu, Arm, February 2019
Resources
- RA8M1 product details and documentation
- Revolution of Endpoint AI in Embedded Vision Applications blog
- Read the App Note to learn more about the performance advantages of the RA8 MCUs with Helium