

TinyML(Tiny Machine Learning)はエッジデバイスで機械学習モデルを実行することで、プライバシーの強化、クラウド接続からの独立性、コストと電力効率などのメリットを引き出すことができます。しかし、これらのモデルを量産に移行するには独自の課題があります。ルネサスはe-AIトランスレータでこの課題を解決します。PyTorch、TensorFlow Lite、Kerasなどの有名なフレームワークのMLモデルをCソースコードに直接変換することで、MLと組み込みエンジニア間のコラボレーションがより円滑になります。このブログでは、クラウドキットCK-RA6M5とe-AIトランスレータを使用し、MLモデルの作成からマイコンへの組み込みまでのユースケースの詳細を記載したアプリケーションノートをご紹介します。
CK-RA6M5
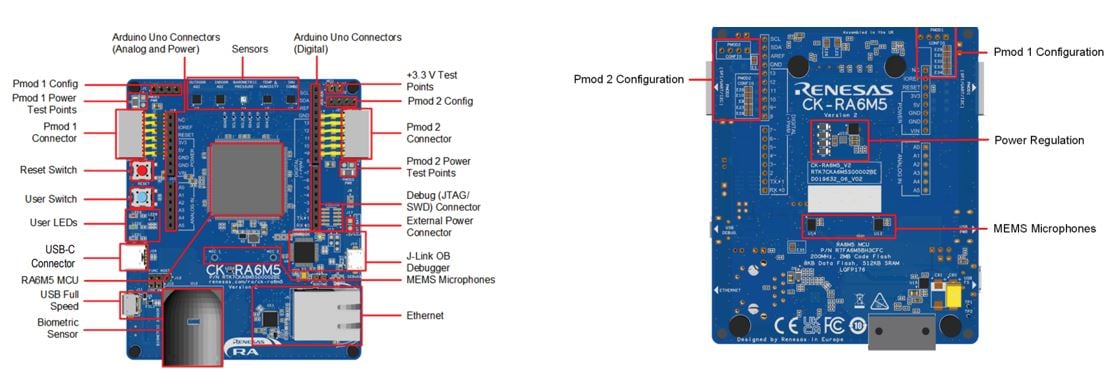
ルネサスのCK-RA6M5クラウドキット[図1]は、Arm® Cortex-M33®ベースのRA6M5MCUグループの豊富な機能とクラウド接続ソリューションを活用できる最先端ソリューションです。
クラウド接続:
- LTEセルラーCAT-M1モジュールRYZ014A:安全で信頼性の高いクラウド接続が可能
- イーサネットオプションは、さまざまなネットワーク要件に対応
センサ:
- 湿度と温度
- 屋内および屋外の大気質指数
- 健康関連:心拍数、SpO2(血中酸素飽和度)、呼吸数
- 気圧と9軸モーショントラッキング
- さまざまなオーディオアプリケーション用の2つのMEMSマイクロフォン
オンボードMCU:RF7A6M5BH3CFCマイクロコントローラ:
- Arm Cortex-M33コアで200MHzの高速動作
- 2MBのコードフラッシュを512KBのSRAMで補完
- 小型の176ピンLQFPパッケージ
その他の特徴:
- USBフルスピード、ホストとデバイスの両方に対応
- Arduino™ (Uno R3)コネクタにより、さまざまなモジュールとの互換性を確保
- Renesas Flexible Software Package(FSP)により、FreeRTOS、Azure RTOS、その他の重要なミドルウェアスタックを統合
CK-RA6M5キットはクラウド接続を容易化し、商品企画から市場投入までの迅速な移行をお客様へ提供します。

e-AIトランスレータ
前述したように、e-AIトランスレータは、一般的なフレームワークで開発したAIモデルをCソースコードに変換するためにルネサスが開発したツールです。フレームワークは、PyTorch、TensorFlow lite、Kerasです。図 3がe-AIトランスレータのGUIです。

図 3 の番号は、変換実行の手順を示しています
- ML モデルの開発に使用するフレームワークを選択します。
- 変換で推論速度を優先するか、RAM使用量を優先するかを選択します。
- AI モデル ファイルを選択します。
- 出力形式を選択します。
FP32形式、INT8形式、もしくはArm社のCMSIS-NN形式が選択できます。
特にCMSIS-NNでは実行速度の大幅な向上が期待できます。 - 変換されたされたCソースコードを出力するフォルダを指定します。
- 変換を実行します。ソースファイルやchecker_log_output.txtファイルなどが出力されます。checker_log_output.txtファイルからRAM / ROMの使用状況を確認できます。
e-AIトランスレータの詳細については、Webサイトにアクセスし、e-AIトランスレータのユーザーズマニュアルをご確認ください。
エンドポイントの音声認識を実現するための全体ワークフロー
このセクションでは、データ前処理から組み込みアプリケーションコードへの変換まで、キーワード音声認識のTinyML開発フロー全体をアプリケーションノート内で図4のようにご紹介しています。この例では、Googleが公開しているオープンソースのキーワード音声認識データセット[4]を活用しています。
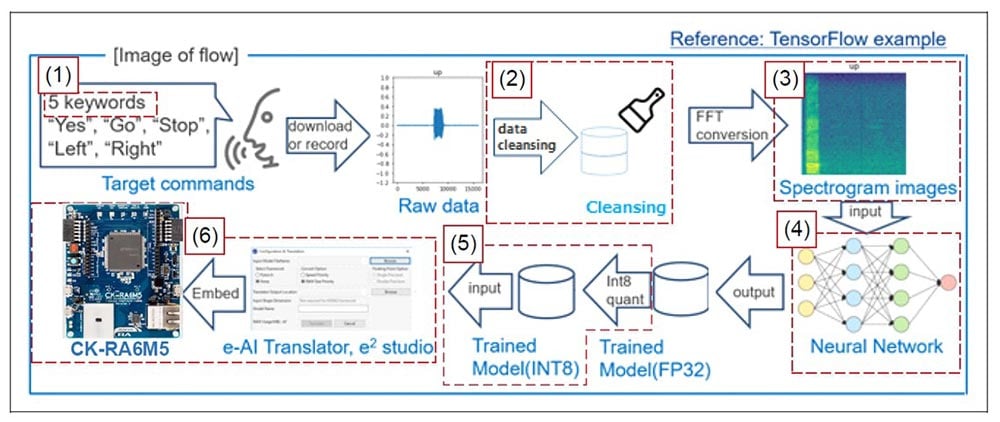
- 対象キーワード: デモを容易にするために、今回の音声キーワード認識で使用するのは、go、left、right、stop、yes の 5 つに制限しています。
- 前処理: 深層学習では、ノイズの多いデータや不完全なデータによって、モデルの精度が低下する場合があります。今回はMCUに実装するという制約があるため、利用可能なモデル容量が限られています。これを考慮し、効率的な前処理技術が採用されています。
- データクレンジング: 今回の例ではデータクレンジングとして、音量を一定にするために録音レベルを増幅または減衰させています。その後、無音のデータやノイズのみのデータなど異常なデータを削除して、理想的な音声データのみが保持されるようにしています。さらに無音部分を切り取り、音声データの開始位置を揃えています。
- スペクトログラムへの変換: 今回、AIモデルとしては画像処理に使用される畳み込みニューラルネットワークが採用されているため、音声データはスペクトログラム画像に変換した上で使用します。スペクトログラム画像は時間とともに変化する信号の周波数スペクトルを視覚的に表現したものです。マイクロコントローラのメモリ容量を小さくするために、スペクトログラムのデータサイズは64×62ポイントに制限しています。一方、Google mini–Speech Commandsデータセットは16,000Hzのサンプリングレートで1秒のオーディオクリップに合わせて調整されています。今回は、隣接するポイントを平均化してデータ量を減らし、これらのメモリ制約内でキーワード音声認識を実現しています。
- ニューラルネットワーク: 今回使用したニューラルネットワークでは90%以上の精度を実現しています。ニューラルネットワークの構成は、2つの畳み込み層、2つのmaxpooling層、および全結合層です。TensorFlow Keras APIを使用して設計しています。
- トレーニング済みモデルの構成: トレーニング後のモデルはINT8形式に量子化され、精度に影響を与えることなくメモリ使用率を削減しています。量子化時の精度劣化を防ぐため、代表的なトレーニングデータを使用してモデルをキャリブレーションしています。
- e-AI Translatorを使用したCK-RA6M5ボードへの実装: 前のセクションで説明したように、e-AI Translator は .H5ファイル等をCソースコードに変換します。変換したCソースコード内の推論関数は組み込み用プロジェクトから呼び出すことで活用できます。次に、図5に示すように、CK-RA6M5ボードを使用してアプリケーションコードを開発します。アプリケーションノートにはサンプルアプリケーコードも同梱していますのでこちらもご活用ください。
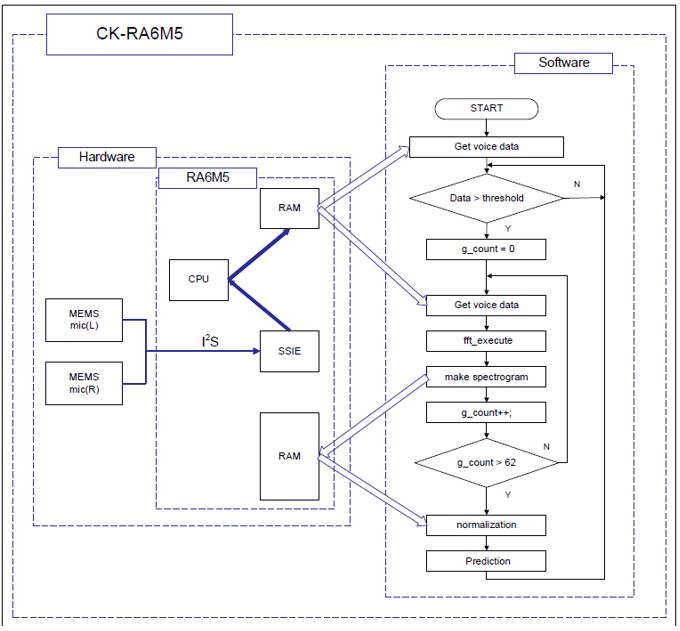
デバイス上でアプリケーションコードを実行します。次の動作が確認できます。
- 最初にLEDが点灯します。システム初期化中のため、まだ音声は入力できません。
- LEDが消灯すると準備完了です。音声入力待機状態となります。
- 音声を検出するとLEDが1秒間点灯します。音声認識が行われます。
- CK-RA6M5は、1秒間の音声入力を前処理した上で推論を行います。
(前処理内容:増幅、左揃え、FFT、正規化) - 推論の結果は、CK-RA6M5のLED点滅で示されます。
- 「Go」の場合は1回点滅
- 「Left」の場合は2回点滅
- 「Right」の場合は3回点滅します
- 「Stop」の場合は4回点滅します
- 「Yes」の場合は5回点滅します
AIアプリケーション開発を開始するお客様は、是非このアプリケーションノートをご確認いただき、e-AIトランスレータを効果的にご活用ください。
今回ご紹介した前処理、モデル開発、組み込みアプリケーションプロジェクトの詳細およびスクリプトについては、マイクロコントローラ用e-AI開発環境のWebページにアクセスし、「チュートリアルガイド」のアプリケーションノートにアクセスしてください。
リファレンス
[1] マイコン向けe-AI開発環境
[2] CK-RA6M5
[3] RA6M5 マイクロコントローラのウェブページ
[4] Pete Warden, "Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition", Apr. 2018