
半導体メモリの主力製品であるDRAMは、その大容量の記憶容量と、データやプログラムコードをホストプロセッサに迅速に入力できることで、業界内では確固たる地位を築いています。
最近では、回路基板の縁の下の力持ちとなるこのDRAMが、昨今、ライバルとも言えるロジック製品に遅れを取っています。AI予測や生成AIアプリケーションの膨大なデータ処理に対応するため、高性能FPGA、CPU、GPU、TPU、カスタムアクセラレータASICなどが続々と登場しているためです。急速に台頭するAIアクセラレータの純粋な演算密度は、最も野心的だと思われた予想をも簡単に飛び越え、データセンタのサーバ内のプロセッサコア数は増大する一方です。
ロジックの高性能化がDRAMのそれを上回り続けているというこの状況下で、ロジックの爆発的な成長はある事態に直面しました。すなわち、このギャップが一因で両者間の性能のミスマッチが拡大し、高速でコストがかかるプロセッサが、メインメモリからデータを運んでくるのを待つ間、計算サイクルを無駄にせざるを得なくなり、サーバの性能を妥協するしかない事態に迫られているのです。
DRAMインタフェース設計への新しいアプローチ
もちろん、このような不均衡は今に始まったことではありません。古典的なフォン・ノイマンモデルの本質はまさにプロセッサとメモリを切り離すことですが、これにより、すべての計算サイクルの最適化を妨げる難所が生じます。システム設計も設備投資ロードマップも、当分はこのアーキテクチャのパラダイムに多かれ少なかれ縛られることになり、それゆえに私たちにはプロセッサとメモリをより緊密に連携させるための新たなアプローチが必要です。
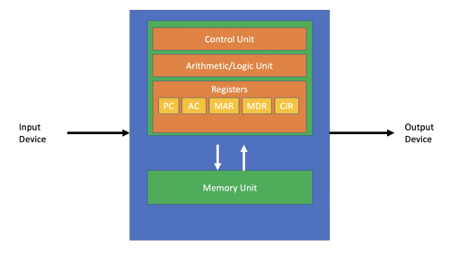
実際、DRAMの設計者は、高速で大容量の第3世代DDR5 DRAMの登場を契機に、このギャップを急いで埋めようとしていますが、演算機能とメモリを調和させるためには、もっと多くのことを行う必要があります。それこそが、ルネサスが第3世代 DDR DRAMサーバおよびクライアントシステム向けにレジスタードクロックドライバ(RCD)とクライアントクロックドライバ(CKD)を発表した理由です。これによりルネサスは、DIMM(Dual Inline Memory Module)、マザーボード、および組み込みアプリケーション向けメモリインタフェースのポートフォリオをさらに拡充しました。
新しいDDR5 RCDおよびDDR5 CKD ICは、現在の転送速度(5,600MT/秒)を向上させ、RCDは最大6,400MT/秒、CKDは最大7,200MT/秒の次世代DIMMを実現します。ルネサスの第3世代DDR5 RCDは、レジスタードDIMM(RDIMM)向けに設計されており、CKDは、スモールアウトラインDIMM(SODIMM)、バッファなしDIMM(UDIMM)、高性能ゲーミングDIMM、およびクライアントプラットフォーム向けのメモリダウンアプリケーションに対応しています。(ルネサスのDDR5 DIMM向けソリューション)
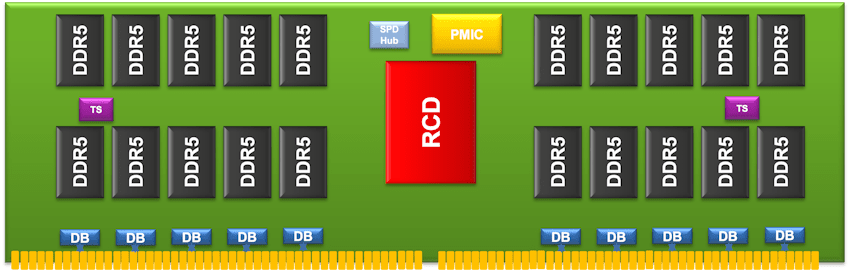
これらのメモリインタフェース製品を組み合わせることで、さまざまな性能、消費電力、容量で動作するメモリを構築できます。今後は、機能やプロセスノード、電気的特性の異なるコンポーネントを1パッケージに統合するヘテロジニアスコンピューティングの新たな形態、いわゆる「チップレット」の成長が期待されています。ヘテロジニアスコンピューティングはまた、サーバ内部、そしてサーバラック全体におけるデバイスやモジュール内のメモリやロジックへの新たなアプローチを研究する原動力ともなっています。
エコシステムによる協業の重要性
私たちは他との関わりなしにこの躍進を成し遂げたわけではありません。ルネサスは、標準化団体 JEDEC と密接に協力することで、開発パートナのエコシステムを促進し、DRAMやDIMMのメーカ、CPUやGPU、およびその他のロジック半導体プロバイダ、サーバ設計者、さらにはAmazonやGoogle、Microsoftのようなハイパースケールコンピューティングの事業者を結びつける役割を果たしています。共通のロードマップやKPI(重要業績評価指標)を設定するだけでなく、共同体として、デバイス、モジュール、システムの各レベルで、さらに関連するソフトウェアアプリケーション全体にわたって、設計検証と相互運用性テストを確実に実施しています。
また、緊密な連携が不可欠であることから、私たちは Compute Express Link™(CXL™)コンソーシアム. にも参加することにしました。このコンソーシアムは、データセンタを相互接続するためのオープンソース標準と技術仕様の開発を目的としています。これには、さまざまな形態のコンピューティングシステムアーキテクチャと同等の性能を達成する高速メモリに関しても含まれています。
ルネサスの最終的な目標は、デバイス、モジュール、そしてシステムの設計に、従来の設計制約を打ち破る力を与えることです。私たちが力を合わせることで、コンピューティングとメモリの最適なアーキテクチャを引き出し、ますます高度化するコンピューティング集約型のAIアプリケーションのニーズをより的確に満たすことができるのです。
ニュース&各種リソース
| タイトル | 分類 | 日時 |
|---|---|---|
| DDR5メモリモジュール用に、第3世代レジスタードクロックドライバおよび、第1世代クライアントクロックドライバを発表 | ニュース | 2023年6月28日 |